
AI
Designing AI for Researchers: Lessons from 6 Months of Remy

.png)

.png)
Read Article

.png)
.png)

Anthony Lam
February 25, 2026
Market Research
Articles
AI
Designing AI for Researchers: Lessons from 6 Months of Remy
Learn More
Anthony Lam
February 25, 2026
Market Research
Articles

AI
64 AI Market Research Prompts for Data Analysis
Read Article
February 25, 2026
Market Research
Articles
AI
64 AI Market Research Prompts for Data Analysis
Learn More
February 25, 2026
Market Research
Articles

Advanced Research
9 Essential Questions for Evaluating Employee Satisfaction Software
Read Article
February 20, 2026
Employee Research
Articles
Advanced Research
9 Essential Questions for Evaluating Employee Satisfaction Software
Learn More
February 20, 2026
Employee Research
Articles

Advanced Research
How to Evaluate Market Research Vendors for Global Reach
Read Article
Team Remesh
February 10, 2026
Market Research
Articles
Advanced Research
How to Evaluate Market Research Vendors for Global Reach
Learn More
Team Remesh
February 10, 2026
Market Research
Articles

Advanced Research
3 Early-Stage Research Methods to Gather Consumer Insights
Read Article
Team Remesh
January 27, 2026
Market Research
Articles
Advanced Research
3 Early-Stage Research Methods to Gather Consumer Insights
Learn More
Team Remesh
January 27, 2026
Market Research
Articles
.avif)
Advanced Research
Why Agencies Should Embrace AI Tools for Market Research
Read Article
Team Remesh
January 26, 2026
Articles
Advanced Research
Why Agencies Should Embrace AI Tools for Market Research
Learn More
Team Remesh
January 26, 2026
Articles

Advanced Research
The Top Market Research Companies for the CPG Industry
Read Article
Team Remesh
January 20, 2026
Market Research
Articles
Advanced Research
The Top Market Research Companies for the CPG Industry
Learn More
Team Remesh
January 20, 2026
Market Research
Articles

Advanced Research
The Most Cutting-Edge Consumer Insights Software of 2026
Read Article
Team Remesh
January 5, 2026
Market Research
Articles
Advanced Research
The Most Cutting-Edge Consumer Insights Software of 2026
Learn More
Team Remesh
January 5, 2026
Market Research
Articles
Research 101
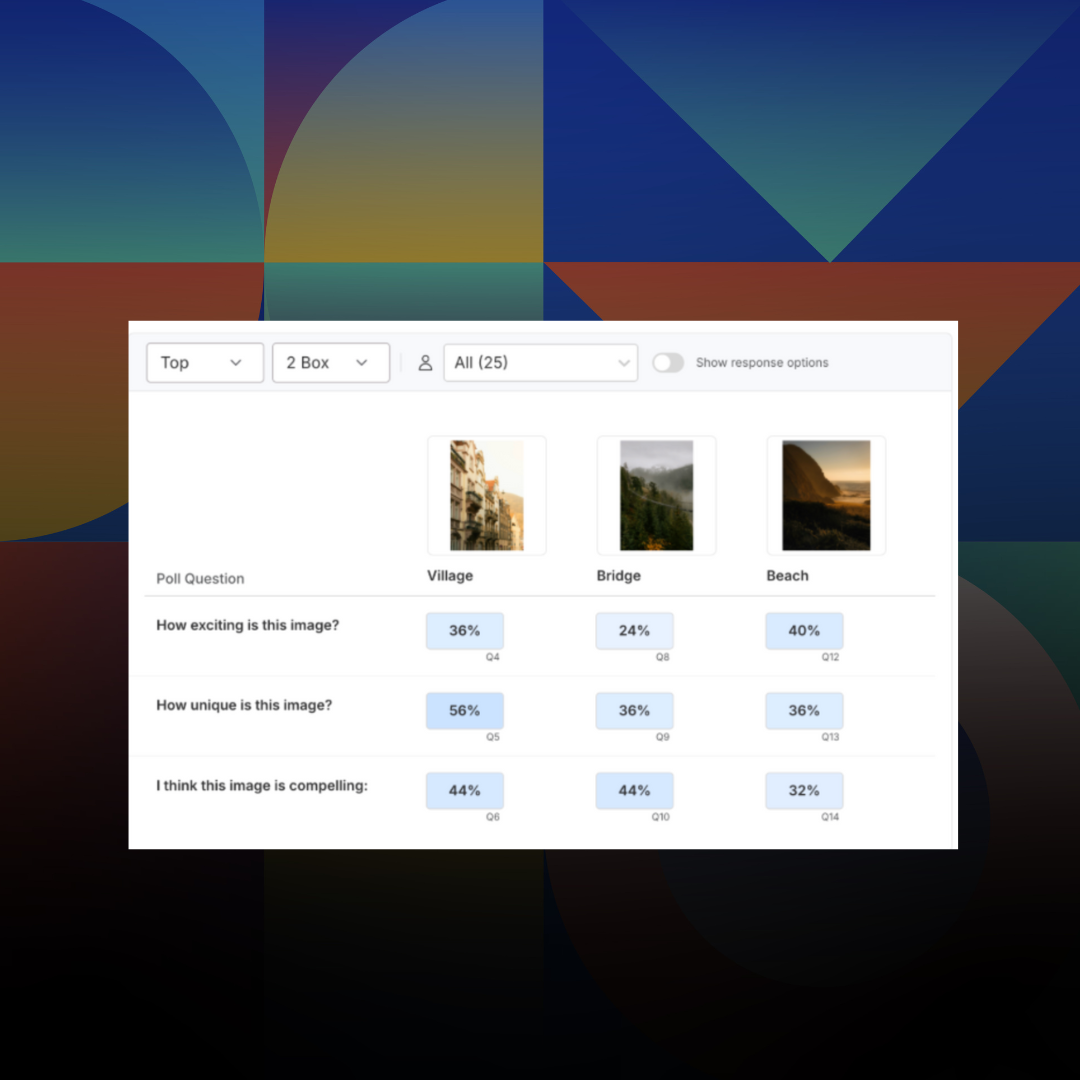
Introducing: Poll Comparison - Streamline Concept Testing and Make Better Decisions Faster
Read Article
Emmet Hennessy
November 24, 2025
Market Research
Articles
Research 101
Introducing: Poll Comparison - Streamline Concept Testing and Make Better Decisions Faster
Learn More
Emmet Hennessy
November 24, 2025
Market Research
Articles
AI Analysis for Qualitative Research
As Large Language Models (LLMs) become increasingly sophisticated, qualitative researchers are discovering their potential to assist with data analysis.

.avif)
As Large Language Models (LLMs) become increasingly sophisticated, qualitative researchers are discovering their potential to assist with data analysis. This document explores some of the technical aspects of leveraging LLMs for qualitative research, followed by practical approaches researchers should consider when incorporating these tools into their workflow.
Part 1:Technical Considerations for LLM-Assisted Qualitative Research
LLMs have democratized how many people consume and parse information. When approaching the task of qualitative data analysis using LLMs, researchers have several methods available to them. Each approach offers different benefits and challenges depending on the scope and complexity of the analysis task.
Methods of LLM Interaction
Web-Based Chat Environments
The simplest approach is using default web-based chat interfaces like ChatGPT.com or Claude.ai. While these platforms offer straightforward interaction, they may lose file context during extended sessions. This approach works well for focused tasks with succinct data, such as analyzing a single set of verbatim responses or identifying themes in a specific dataset. However, more complex analyses requiring multiple iterations or cross-referencing between different data sets may not produce the most inclusive answers.
Focused Knowledge Bases
Creating dedicated knowledge bases within chat environments, such as Custom GPTs or Projects within ChatGPT or Claude, provides more stable data context. While this approach requires more initial setup time, it prevents the need to repeatedly upload data and maintains consistent context across sessions. This can be particularly valuable for ongoing research projects or when working with complex, multi-faceted datasets.
API Integration
The most robust but technically demanding approach involves interacting with LLMs through their APIs, whether via command line or web-based API sandboxes (sometimes called “playgrounds”). This method offers the most comprehensive file handling and data analysis capabilities but requires some technical expertise to implement most effectively. As an example of file handling limitations between interaction types. OpenAI’s ChatGPT supports up to 20 files uploaded per chat, Custom GPT or Project in the web interface. On the other hand, OpenAI’s developer API or sandbox supports 20 files for their Code Interpreter Tool (used for code-based tasks) and 10,000 files for their File Search Tool (used for including additional data context for tasks). Management of files – including additions and removals – is much more flexible with API interactions as well.
Data Handling and Context Windows
Working with data files in LLM environments requires understanding a few technical aspects. The most fundamental of these is the context window limitation, which functions like the model's short-term memory. This context window determines how much text the model can process simultaneously, with larger context windows aligned to capacity for more data. This is a factor to consider for researchers needing to work with large datasets or who want to analyze many datasets at once.
The following table shows select File Support and Context Window attributes for some popular models available at time of writing (March 2025) that could be a good fit for use on data acquired on the Remesh platform.
To get a sense of scale for a typical dataset, we evaluated a comprehensive data CSV from a medium-large Remesh study. Our Consumer Habits Study with 530 participants responding to 20 questions (both closed and open ended) comprises about 250K tokens of text. While this exceeds some models’ context windows, LLMs employ sophisticated methods for structured spreadsheet data (and other data types), though these approaches come with their own set of tradeoffs and limitations.
Technical Considerations and Limitations
Data Scope
When given analysis tasks, LLMs typically make autonomous decisions about which parts of a dataset to examine unless explicitly directed otherwise. For tabular or spreadsheet data, the process often starts with the model making a decision about the scope of data it requires for further processing. This can lead to a narrow focus on obvious matches while missing other contextually relevant information that might be crucial to user questions.
The challenge becomes particularly apparent when important underlying data exists in unexpected locations within the dataset. An LLM's programmatic approach might not account for indirect or subtle relationships between different data points, potentially overlooking valuable connections that a human researcher would recognize. This limitation underscores a researcher’s familiarity with data.
For example, in our Consumer Habits Study, our query to ChatGPT “What are the primary consumer shifts as surfaced by this study?” sourced data from 4 questions to formulate an answer (1 qualitative question and 3 quantitative questions).
- The model successfully identified that relevant data was in the qualitative question column for “How, if at all, has your relationship with your most used brands or products changed since the pandemic (for better, or for worse)?”
- The model also missed at least two additional columns of data for qualitative question columns like “What is important to you now (what are your priorities)?” and “What new routines or behaviors have you started, based on what you now think is important?”
When the researcher guides the analysis scope based on their understanding of the data's structure and context, better results are achieved. A tip to remember is that LLM users can always ask the model 1) how answers were formulated and 2) what assumptions were made to produce the answer. Users can also ask that specific columns of data be included if some are deemed missing.
Data Processing
In all three methods of interaction, LLMs typically approach analytical tasks through code-based tools, writing custom code and using standard code libraries in languages like Python (GPT) or JavaScript (Claude). For those who are technically savvy, the underlying code produced to perform analysis is always available to the user for transparency. Within the web chat environment, the functions employed by LLMs will excel at fundamental tasks such as text matching, frequency analysis, pattern recognition, statistical computations, and topic clustering. They can handle structured queries and perform simple similarity calculations, though their ability to understand semantic relationships may be limited.
The following are some examples of qualitative analysis tasks where a web-based chat LLM would excel:
- Keyword based search:
Find responses mentioning “food delivery,” “Uber Eats,” “DoorDash,” “grocery delivery,” “spend more,” “ordering online”. - Sentiment analysis (basic):
Please determine the sentiment (positive, neutral, negative) of the responses about increased spending. - Frequency analysis:
Please identify the most common words and phrases in responses related to spending and list their frequency count. - Topic clustering:
Group the responses to question 15 into the following categories - convenience spending, health-conscious purchases, cost concerns.
Advanced Analysis Requiring External Tools
More sophisticated analysis techniques might require specialized tools beyond what is available in the web chat interface. Advanced tasks such as vector embedding generation, semantic similarity search, and deep contextual analysis need dedicated external infrastructure. Overall, these tools produce deep relationships within and across text based on meaning by way of mathematical representations – these unlock nuanced patterns in qualitative data that otherwise might not be surfaced. Another big benefit of this kind of vector-based approach is the content is not inherently limited by context windows, since data is represented numerically. The following are some examples of qualitative analysis tasks where a web-based chat LLM would might be more challenged, and where other methods of interactions like Focused Knowledge Bases (e.g., Projects or Custom GPTs) and API interactions might excel:
- Flexible semantic search (where user does not have to specify specific keywords):
Find all responses similar to increasing spending on food delivery. - Sentiment analysis (advanced):
Please determine the sentiment of the responses about increased spending, using positive, neutral, negative, but also use other emotional descriptions if necessary for responses deemed mixed, ironic or sarcastic. - Name entity recognition:
Please extract all brands, stores, locations, or services mentioned by participants and classify them with those labels. - Contextual predictive capability (text and sentiment context):
Relating a response like Food delivery has been a lifesaver for our family, we have been ordering weekly meal kits to High likelihood to continue using food delivery services.
Powerful to be sure, but a process that may require expertise and implementation with solutions external to an LLM provider. Vendors like OpenAI offer some of these tools directly via their API service.
File Types
The way these environments handle files also varies significantly depending on the type and format of data being processed. For instance, structured data like spreadsheets might be processed differently than raw text files or PDFs or DOCX files, each with their own set of capabilities and limitations. These constraints do not necessarily prevent effective analysis, but do require researchers to be thoughtful about how they approach their data analysis tasks. Newer models are supporting an increasing number of file types for a wider set of use cases.
Implementation Considerations
Choose the Right Tools
When implementing LLMs for qualitative analysis, researchers should carefully select appropriate tools based on their specific needs. Chat interfaces work well for initial exploration and structured analysis, while vector-based tools that can require external tools may be necessary for deeper semantic analysis. Many research projects benefit from a hybrid approach that leverages the strengths of different tools at various stages of the analysis process.
Plan for Scale
Effective LLM implementation requires thoughtful planning for data scale and structure. Researchers should consider file size and format limitations when designing their data collection, potentially breaking large datasets into manageable chunks when necessary. Structuring data with analysis in mind from the outset can significantly simplify the LLM-assisted analysis process.
Validate and Verify
Crossreferencing LLM insights with manual analysis remains an essential way to ensure research quality. Researchers can use multiple analysis approaches for important findings while documenting analysis procedures, decisions and limitations involved. Ways that users can apply multiple approaches include some of the following:
- Run the same analysis prompts across different models (see the next section Observations from Our Head-to-Head Comparison)
- Re-run the same prompt at different points in the same session or a different one within the same model
- Ask how the models arrived at an answer, and what assumptions were made
- Include additional information or point to specific columns or blocks of data
- Ask the model to ask the user what additional information might be required to complete the analysis tasks, for example including something like this at the end of an analysis prompt:
When performing this analysis task, if you are unsure of data scope or what decisions to make along the way, ask me for input.
These kinds of validation help maintain research integrity while leveraging the efficiency advantages of LLMs.
Observations from Our Head-to-Head Comparison
We ran a comparison of several popular models on our Consumer Habits study, using the file upload feature on the web-based chat environment across the same 12 qualitative analysis questions. We opted not to use knowledge base or API approaches to ensure the most level playing field in terms of user ease-of-access and technical capability (i.e., not all services had a Projects feature for knowledge base interaction or an API sandbox). The models tested are listed below:
- GPT 4o
- Claude Sonnet 3.5 (locked behind paywall at time of testing)
- Gemini 1.5 Pro (locked behind paywall at time of testing)
- Gemini 2.0 Flash
We used two data files, a comprehensive data file with each participant’s responses and high level file from our Summarize feature. To prepare the data file, we removed some of the header rows (non-essential information like conversation name, date, and time) focusing just on question and answer data to ensure smooth processing. Any pertinent information from the header was supplied directly alongside with the file.
Overall, Claude Sonnet 3.5 and Gemini 2.0 Flash were the most well-rounded performers, providing answers that were consistently readable and understandable. Claude was more verbose than Gemini 2.0, but Gemini 2.0 would sometimes cite specific columns of data used to produce answers without additional prompting.
GPT 4o and Gemini 1.5 Pro performance was noticeably weaker. For a number of questions, GPT 4o produced a series of crowded tables that were relevant but required some user interpretation. GPT 4o also struggled to determine emotional trends while other models were able to surface them. Gemini 1.5 Pro lost file context and asked the user to re-upload the file, and also completely errored out (totally unable to proceed) before completing all questions. While newer models than the ones evaluated are already available (GPT 4.5 and Sonnet 3.7), it is likely that their performance is similar given that most advances are in the domain of coding competencies.
Some examples of the outputs that give a sense of quality of responses from each model are included in this Sheet.
Part 2: Best Practices for LLM-Assisted Qualitative Research
With an understanding of the technical landscape, researchers can implement practical strategies to maximize the effectiveness of LLMs in their qualitative analysis workflow.
Start with Manual Review
Before leveraging LLMs, researchers should begin with a thorough manual review of their data. This foundational step is crucial for developing a deep understanding of the content, identifying emerging themes, and knowing how to guide an LLM through further analysis tasks. This initial review positions researchers to effectively validate assertions and answers offered by an LLM. As previously mentioned, models can define their own scope of focus, so researchers may sometimes observe that answers are valid (accurately reflecting underlying data) but insufficient (inclusive of too little underlying data) to answer their question. Having a firm grasp on the data helps the researcher steer and course correct as necessary to proceed through analysis work. As with any use of an LLM, the highest quality outputs stem from as much user supplied context and thoughtfulness as possible. Qualitative data research and analysis is no exception – the most trustworthy answers and insights are curated by a guiding researcher armed with knowledge.
Build Context Through the Research Process
Successful implementation of LLMs in qualitative research relies heavily on the researcher's accumulated knowledge throughout the study. This process begins during guide development, where key themes and areas of interest first emerge. As the research progresses, researchers should document client priorities and track patterns that surface during data collection. This accumulated context serves as a crucial framework for guiding and validating LLM analysis, ensuring that automated insights align with the study's objectives and emerging patterns.
Develop Effective Prompting Strategies
Working effectively with LLMs requires careful attention to how queries and instructions are framed. Researchers should craft clear, specific prompts that guide the LLM toward desired outputs. This includes specifying the use of present tense in synthesized outputs to maintain consistency and requesting high-quality business language when appropriate for professional reporting.
An example here might look something like:Please synthesize together these 3 paragraphs of text that are all derived from the data from a single question from my qualitative study. Each paragraph emphasizes a different audience demographic, which is noted at the beginning. Please use present tense language, maintain a professional business tone, and avoid hyperbole. Be clear without outputs, focusing on data findings rather than making recommendations.
Importantly, researchers should establish clear guardrails in their prompts, such as avoiding hyperbole and focusing on findings rather than recommendations. These prompting strategies help ensure that LLM outputs remain focused and relevant to research objectives.
Implement a Multi-Stage Analysis Process
Effective qualitative analysis with LLMs follows a structured, iterative approach that begins with initial data review and familiarization. Researchers should then progress through analysis of quantitative metrics and charts before conducting detailed, question-by-question analysis. LLM synthesis can then be employed to integrate findings across questions and generate comprehensive insights. This staged approach ensures thorough coverage of the data while maintaining analytical rigor.
Maintain Critical Oversight
The role of researcher judgment remains paramount when working with LLMs. Every automated insight should be evaluated against the researcher's understanding of the raw data. This means verifying unusual or unexpected findings, assessing whether highlighted insights are truly representative or merely outliers, and ensuring that LLM summaries align with observed patterns. Researchers must consistently apply their domain expertise to evaluate the relevance and importance of LLM-generated insights.
Key Takeaways from Best Practices:
- Always start with manual data review to build foundational understanding
- Use accumulated research context to guide LLM analysis
- Create clear, specific prompts with appropriate constraints
- Follow a structured, multi-stage analysis process
- Maintain active oversight and validation of LLM outputs
Conclusion
LLMs offer powerful capabilities for qualitative research analysis, but successful implementation requires understanding both technical limitations and practical best practices. By beginning with a clear understanding of the technical landscape and available tools, researchers can make informed decisions about how to integrate LLMs into their workflow. Then, by following established best practices for implementation, they can ensure that these powerful tools enhance rather than replace their expertise and analytical judgment.
The future of qualitative research likely involves a thoughtful balance of human expertise and technological assistance. By embracing this hybrid approach with awareness of both capabilities and limitations, researchers can leverage LLMs to enhance their analytical capabilities while maintaining the depth and nuance that makes qualitative research so valuable.
-
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
-
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
-
More
.png)
Nestlé captures early stage advertisement campaign feedback for prelaunch optimization
Read More
Learn More
Stay up-to date.
Stay ahead of the curve. Get it all. Or get what suits you. Our 101 material is great if you’re used to working with an agency. Are you a seasoned pro? Sign up to receive just our advanced materials.

